-
首頁
-
網站建設
-
優化推廣
-
案例
方案

方案
Solutions
電商平臺

電商網站開發
E-commerce & System
微信營銷
資訊
我們

我們
About Us
聯系

聯系
Contact Us
-

- 聯系方式
- 業務熱線: 15082661954
- 郵箱: foxl@www.kxlw.net

- 人才招聘
- HR郵箱:
- 190014322@qq.com












































精準傳達 ? 價值共享
洞悉互聯網前沿資訊,探尋網站營銷規律
采集俠定向規則采集
作者:Smileby陌少羽 | 2019-04-21 10:21 |點擊:
1、設置定向采集
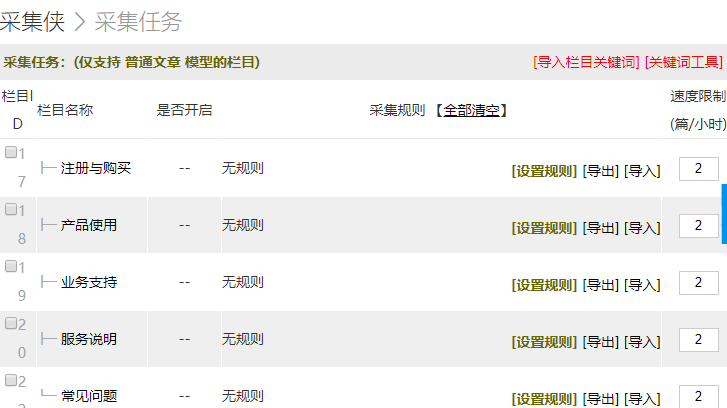
1)、登錄您網站后臺,模塊->采集俠->采集任務,如果您的網站還沒有添加欄目,你需要先到織夢的欄目管理里先添加欄目,如果已經添加了欄目,你可能可以看到如下界面
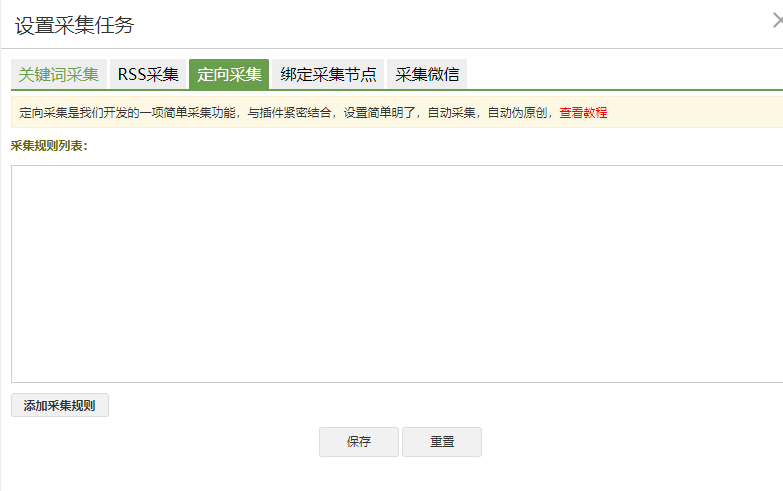
2)、在彈出的頁面里選擇定向采集,如圖所示
3)、點擊添加采集規則,這就是添加定向采集規則的頁面了,這里我們要詳細說下
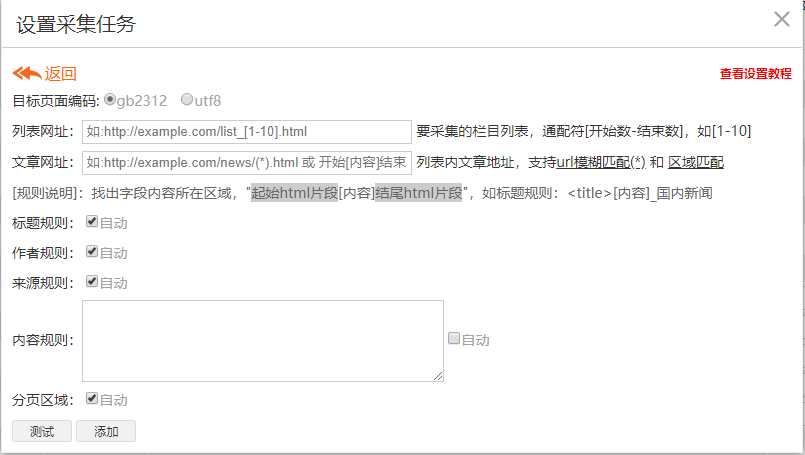
2、設置 目標頁面編碼
打開您要采集的網頁,點擊鼠標右鍵,點擊查看網站源碼,搜索charset,查看charset后面緊跟的是utf-8還是gb2312,如圖所示即為utf-8
3、設置 列表網址
列表網址就是您要采集的網站的欄目列表地址如果只是單純采集列表頁的第一頁,直接輸入該列表URL就行,如我要采集站長之家的優化欄目的第一頁,那列表URL就輸入:http://www.chinaz.com/web/seo/,即可。采集第一頁的內容的好處就是可以不用采集老舊的新聞,而且有新更新也可以及時采集到,如果需要采集該欄目的所有內容,那也可以通過設置通配符的方式,匹配所有列表URL規則。
匹配URL規則的方法也很簡單,你只需要查看列表分頁的不同,加個通配符即可,如站長之家的優化欄目:
第一頁的URL是:http://www.chinaz.com/web/seo/1.shtml
第二頁的URL是:http://www.chinaz.com/web/seo/2.shtml
第三頁的URL是:http://www.chinaz.com/web/seo/3.shtml
通過觀察列表URL的變化,可以看出第一頁就是1.shtml,第二頁就是2.shtml,第三頁就是3.shtml,變換的就是頁碼而已,列表頁的URL通配符是 [開始頁-結束頁] ,假如你要采集欄目前二十頁的,那么列表URL規則就是:http://www.chinaz.com/web/seo/[1-20].shtml,看到其中的區別了吧,就是在變換的部分加入通配符,從開始頁到結束頁即可。
4、設置 文章網址
文章URL規則和列表URL規則設置差不多,也是通配變換的部分,只是通配符不一樣而已,文章URL使用通配符 (*) 來匹配,有采集規則編寫經驗的用戶可以很容易理解,通配符可以代替一個或多個真正的字符,通過下面例子更加直觀的了解通配符的使用方法。例:
比如我要采集站長之家優化欄目里面的文章,他們的文章URL是
http://www.chinaz.com/web/2011/0926/211708.shtml
http://www.chinaz.com/web/2011/0926/211705.shtml
http://www.chinaz.com/web/2011/0926/211694.shtml
通配后的URL就是:http://www.chinaz.com/web/(*)/(*)/(*).shtml
也就是說數字部分是變換的部分,可以看得出他的URL結構是年/月日/文章ID的形式,年月日和文章ID是會變換的,所以就通配這三部分內容就行。
我們可以輸入列表URL規則和文章URL規則,然后點擊測試,會看到下圖的測試結果,也就是匹配成功了,已經列出成功匹配的列表URL和文章URL,測試的時候只顯示前十條結果以供觀察是否已經匹配成功。
5、設置 標題、作者、來源、內容、分頁規則
首先這個規則采集俠默認都是自動識別的,但是自動識別的效果有可能沒有自己設置的好,也有可能有的網站采集俠識別不了,如果標題和內容采集俠識別不到那么就什么都采集不到了!所以這里建議是內容規則最好手工設置,而作者和來源規則可以不設置,也可以到采集俠的高級設置菜單里設置成固定的作者以及來源。
標題、作者、來源、內容和分頁規則的寫法都是一樣的,懂得其中一項的寫法,其他幾項都懂得了,所以這里就以內容規則來舉例說明。
采集俠是怎么根據你的規則找到文章內容的呢,其實就是你寫個規則告訴它文章從哪里開始,從哪里結束,最后寫成規則就是 開始的地方的代碼[內容]結束的地方的代碼,
比如我要采集站長之家優化欄目里面的文章,打開文章列表中其中一篇,
如:
http://www.chinaz.com/web/2015/0702/418785.shtml
打開后,右鍵查看源碼,通過查看源碼找到文章處,你可以通過搜索文章中的句子去找文章所在的大概位置
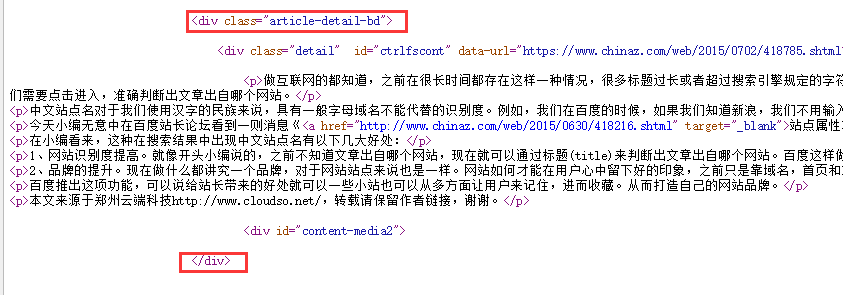
最后我們把前后的代碼做成規則,就是
<div class="article-detail-bd">[內容]</div>
最后點擊測試,如果測試成功了點擊保存即可采集




關于狐靈科技
+狐靈致力于互聯網品牌建設與網絡營銷,專業領域包括 網站建設、 SEO優化、移動互聯網營銷、高端網站建設、高端網站設計、品牌網站定制開發、營銷策劃推廣電子商務、移動互聯網營銷、 為不同類型的客戶提供良好的互聯網應用定制解決方案,我們將策略和執行緊密結合,且不斷評估并優化我們的方案,為客戶提供一體化全方位的互聯網品牌整合方案!
我們的優勢
多項網站設計傳播大獎
營銷型網站建設專家
自主研發網站管理系統
B2C電商網站建設供應商
完善的售后服務體系
我們的不同
+在我們的對手消耗大量的時間停留在碎片化的互聯網設計或者程序實現的時候,我們已經開始把數字化品牌建設和網絡傳播進行了整合。我們提供從前期的網站品牌分析策劃、網站設計、創意表現、系統開發以及后續網站運營反饋建議等一系列服務,幫助企業打造創新的互聯網品牌經營模式與有效的網絡營銷方法,為所有謀求長遠發展的企業品牌貢獻全力!
公司地址:重慶市九龍坡楊家坪重百大樓21-8 | 業務熱線:15082661954
Copyright © 2017-2020 Fox spirit Network. 狐靈科技 版權所有 | 渝ICP備19005721號-1
專業團隊為您提供 重慶網頁設計, 品牌網站設計,營銷型網站制作,SEO優化關鍵詞排名推廣等服務,建網站就找狐靈科技! | TAG標簽 | 網站建設地圖 | 網站地圖
